Ollama 环境安装
Ollama 是一个本地大语言模型运行工具,可在实例中拉取并运行 Qwen、DeepSeek、Llama 等模型。
- 官网:Ollama 官网
- 官方文档:Ollama Docs
- 版本发布:GitHub Releases
建议
Ollama 程序可安装在 /root 下,后续保存镜像时会一并保留环境配置。模型文件通常较大,建议将模型目录放到 /root/rivermind-data 数据盘,便于后续按需扩容。
安装前可选检查
如果计划使用 GPU 推理,建议先确认实例可以识别 GPU:
nvidia-smi推荐将模型保存到数据盘。安装前可先检查数据盘剩余空间:
df -h /root/rivermind-data如果需要公网访问,可提前在实例中开放端口。更多说明可参考:开放端口。
| 服务 | 端口 | 目的 |
|---|---|---|
| Ollama API | 11434(默认端口,本文示例) | 提供模型调用接口,供本地命令、Claude Code、Codex 或其他程序访问 |
| Open WebUI(可选) | 18080(本文示例) | 提供浏览器可视化界面,用于选择模型、对话和管理聊天记录 |
开放端口后,可在实例「自定义服务」中复制公网地址。
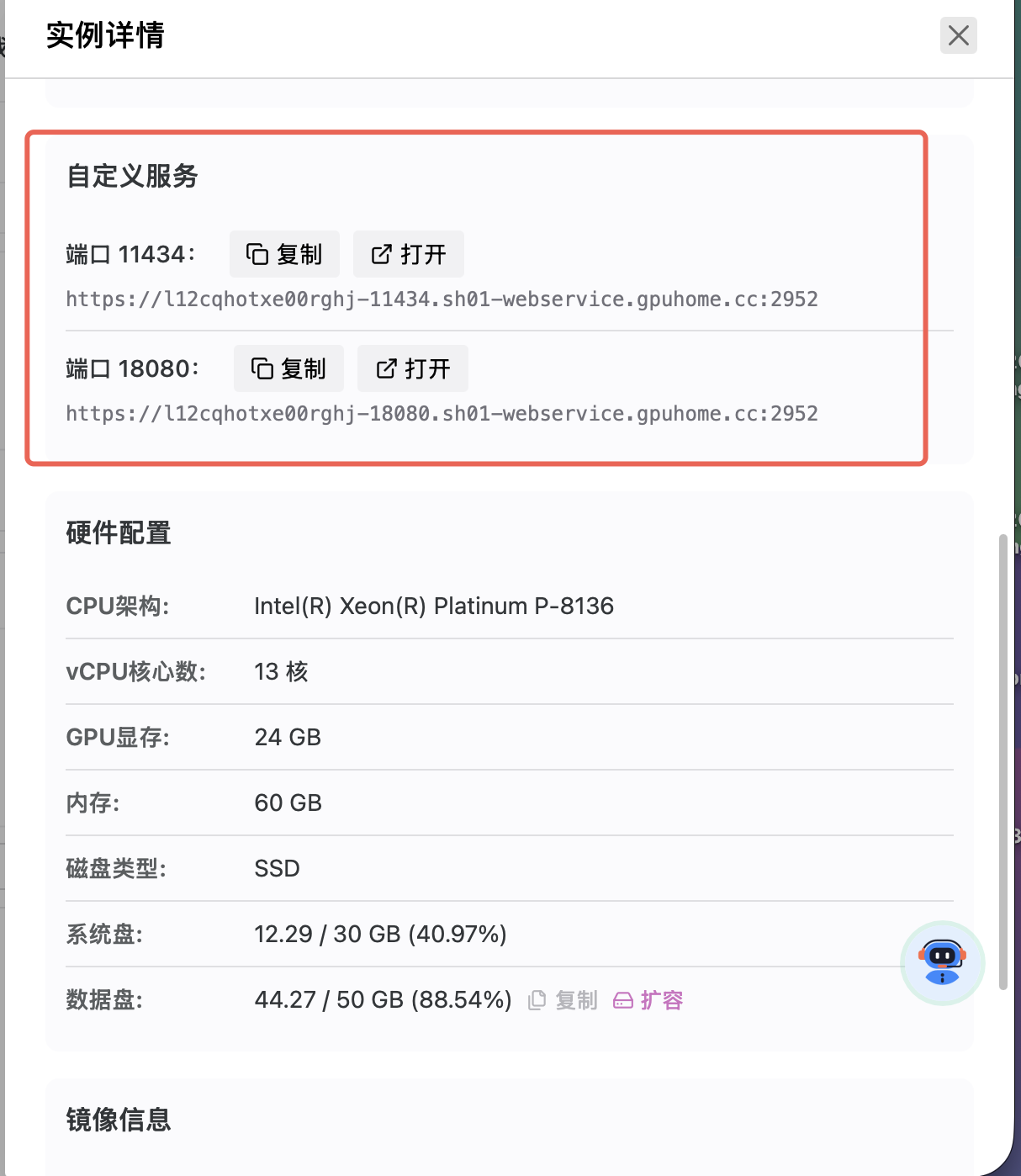
注意
实例开机状态下新增或修改开放端口,需要重启实例后生效。
安装 Ollama
为减少直接访问 GitHub 或拉取 Git LFS 数据时的网络问题,推荐通过 ModelScope 命令行下载 Ollama 安装包。
ModelScope 项目地址:ollama-release
先安装 ModelScope 命令行工具:
pip install modelscope然后下载 Ollama 安装包。普通 x86_64 实例选择 linux-install.sh 和 ollama-linux-amd64.tar.zst 即可。
在 ModelScope 文件页面 找到 master 下拉框,选择需要安装的版本。以下命令以 v0.21.3-rc0 为例,实际使用时请替换为页面中选择的版本号:
cd /root
mkdir -p ollama-linux
cd ollama-linux
modelscope download \
--model=Lixiang/ollama-release \
--local_dir . \
--revision v0.21.3-rc0 \
linux-install.sh \
ollama-linux-amd64.tar.zst执行安装脚本:
chmod +x ./linux-install.sh
./linux-install.sh安装完成后,确认 Ollama 是否可用:
ollama -v确认安装无误后,可清理下载目录:
rm -rf /root/ollama-linux配置模型目录到数据盘
Ollama 默认将模型保存在系统盘,长期使用容易占满空间,建议切换到数据盘。
先创建模型存储目录:
mkdir -p /root/rivermind-data/ollama-models再写入 Ollama 环境变量配置:
cat > /root/ollama-env.sh <<'EOF'
# 指定 Ollama 模型存储目录
export OLLAMA_MODELS=/root/rivermind-data/ollama-models
# 允许从外部访问 Ollama API
export OLLAMA_HOST=0.0.0.0:11434
# 模型空闲后继续保留 1 小时,减少再次调用时的加载等待
export OLLAMA_KEEP_ALIVE=1h
EOF让当前终端和后续新终端生效:
source /root/ollama-env.sh
grep -qxF '. /root/ollama-env.sh' /root/.bashrc \
|| printf '\n# Ollama environment\n. /root/ollama-env.sh\n' >> /root/.bashrc这里只写环境变量,不写启动命令。
后续如需修改 Ollama 环境参数,统一编辑 /root/ollama-env.sh。
启动 Ollama
启动前,建议先停止可能已经运行的旧进程:
pkill -f "ollama serve" || true这一步可以避免旧进程继续使用默认模型目录,导致模型仍然下载到系统盘。
然后在后台启动 Ollama:
nohup ollama serve > /root/ollama.log 2>&1 &确认 API 是否正常响应:
curl http://localhost:11434/api/tags实例启动配置(推荐)
平台容器启动时会执行 /opt/start.sh。不要直接覆盖这个文件,避免影响实例内已有服务。推荐将 Ollama 启动逻辑保存为独立脚本,再把调用命令追加到 /opt/start.sh。
cat > /root/start-ollama.sh <<'EOF'
#!/bin/bash
. /root/ollama-env.sh
if command -v ollama >/dev/null 2>&1 \
&& ! pgrep -f "[o]llama serve" >/dev/null 2>&1; then
nohup ollama serve > /root/ollama.log 2>&1 &
fi
EOF写入后执行:
cd /root
chmod +x /root/start-ollama.sh
# 不覆盖 /opt/start.sh,只追加 Ollama 启动入口
touch /opt/start.sh
grep -qxF 'sh /root/start-ollama.sh' /opt/start.sh \
|| printf '\n# Start Ollama\nsh /root/start-ollama.sh\n' >> /opt/start.sh
# 当前实例立即启动
sh /root/start-ollama.shOllama 日志文件:
/root/ollama.log拉取并运行模型
Ollama 模型库国内网络通常可直接访问,使用官网模型名即可下载。
模型库:Ollama 模型库
以 gemma4 为例,执行以下命令会在模型不存在时自动下载,并在下载完成后进入对话:
ollama run gemma4如果只想提前下载模型,不立即进入对话,可使用:
ollama pull gemma4查看本地已下载的模型:
ollama list模型名称说明
本文后续命令中的 gemma4 仅作为示例模型名。实际使用时,请以 ollama list 输出中 NAME 列的模型名为准;如果模型带有标签,也需要一并填写,例如 gemma4:31b、gemma4:26b 或 gemma4:latest。
示例输出:
NAME ID SIZE MODIFIED
gemma4:31b 6316f0629137 19 GB 5 days ago
gemma4:26b 5571076f3d70 17 GB 6 days ago
gemma4:latest c6eb396dbd59 9.6 GB 6 days ago使用本地模型文件
如果已有本地模型文件,例如 .gguf 文件,可通过 Modelfile 导入到 Ollama。更多说明可参考:Importing a Model。
假设 gguf 文件存放在 /root/rivermind-data/gguf/my-model.gguf(路径可自行选择,与 OLLAMA_MODELS 目录无关,ollama create 会将其注册到模型库):
mkdir -p /root/ollama-local-model
cd /root/ollama-local-model
cat > Modelfile <<'EOF'
FROM /root/rivermind-data/gguf/my-model.gguf
EOF
ollama create my-local-model -f Modelfile
ollama run my-local-model其中 my-local-model 是导入后的模型名称,可按需修改。
API 使用
Ollama API 的调用方式在本地和公网环境中相同,只需要替换基础地址:
| 使用场景 | API 地址 |
|---|---|
| 实例内部访问 | http://localhost:11434 |
| 公网访问 | 实例「自定义服务」中复制的完整地址 |
先根据访问场景设置基础地址:
# 实例内部访问
export OLLAMA_API_URL="http://localhost:11434"
# 公网访问时,替换为实例「自定义服务」中复制的完整地址
export OLLAMA_API_URL="https://你的自定义服务地址"可先调用 /api/tags 查询本地可用模型,确认服务连通:
curl "$OLLAMA_API_URL/api/tags"接口示例
Ollama 原生接口:
curl "$OLLAMA_API_URL/api/chat" -d '{
"model": "gemma4",
"stream": false,
"messages": [
{
"role": "user",
"content": "你好,简单介绍一下你自己。"
}
]
}'OpenAI 兼容接口:
curl "$OLLAMA_API_URL/v1/chat/completions" \
-H "Content-Type: application/json" \
-H "Authorization: Bearer ollama" \
-d '{
"model": "gemma4",
"messages": [
{
"role": "user",
"content": "你好,简单介绍一下你自己。"
}
]
}'Anthropic 兼容接口:
curl "$OLLAMA_API_URL/v1/messages" \
-H "Content-Type: application/json" \
-H "x-api-key: ollama" \
-d '{
"model": "gemma4",
"max_tokens": 1024,
"messages": [
{
"role": "user",
"content": "你好,简单介绍一下你自己。"
}
]
}'公网访问
如需从本地电脑或其他服务访问实例中的 Ollama API,请使用前文开放 11434 端口后得到的公网地址。
注意
开放 Ollama API 后,持有公网地址的人都可能访问该服务。请勿公开分享访问地址,必要时可通过防火墙、网关或上层代理增加访问控制。
前文已配置 OLLAMA_HOST=0.0.0.0:11434。实例启动脚本会加载该配置,重启 Ollama 后即可监听所有网卡。
复制公网地址后,可用 /api/tags 确认服务连通:
export OLLAMA_API_URL="https://你的自定义服务地址"
curl "$OLLAMA_API_URL/api/tags"Claude Code 和 Codex 可通过 Ollama API 调用实例中的模型。以下配置参考 Ollama 官方手动配置方式,将官方示例中的本地地址替换为实例公网地址。官方说明可参考:Claude Code 集成、Codex 集成。
配置 Claude Code
Claude Code 在本地电脑运行,通过 Ollama 的 Anthropic 兼容接口访问实例中的模型。按官方手动配置方式,先用环境变量指向远程服务地址:
export ANTHROPIC_AUTH_TOKEN=ollama
export ANTHROPIC_BASE_URL="https://你的自定义服务地址"
export ANTHROPIC_API_KEY=""
claude --model gemma4其中 gemma4 请替换为实例中实际可用的模型名。
Claude Code settings.json 参考配置
如果希望长期保存配置,也可以写入 Claude Code 的 settings.json。以下示例中的地址、Token 和模型名都需要替换为自己的配置:
{
"env": {
"ANTHROPIC_BASE_URL": "https://你的自定义服务地址",
"ANTHROPIC_AUTH_TOKEN": "ollama",
"ANTHROPIC_API_KEY": "",
"ANTHROPIC_MODEL": "gemma4:31b",
"ANTHROPIC_REASONING_MODEL": "gemma4:31b",
"ANTHROPIC_DEFAULT_HAIKU_MODEL": "gemma4:31b",
"ANTHROPIC_DEFAULT_SONNET_MODEL": "gemma4:31b",
"ANTHROPIC_DEFAULT_OPUS_MODEL": "gemma4:31b"
}
}说明
export 只对当前终端会话生效。关闭终端后需要重新设置;如果只想临时运行一次,也可以将环境变量写在 claude 命令前面。
ANTHROPIC_BASE_URL 填写公网地址根路径即可,不需要追加 /v1。Claude Code 会基于该地址调用 Anthropic 兼容接口,例如 /v1/messages。
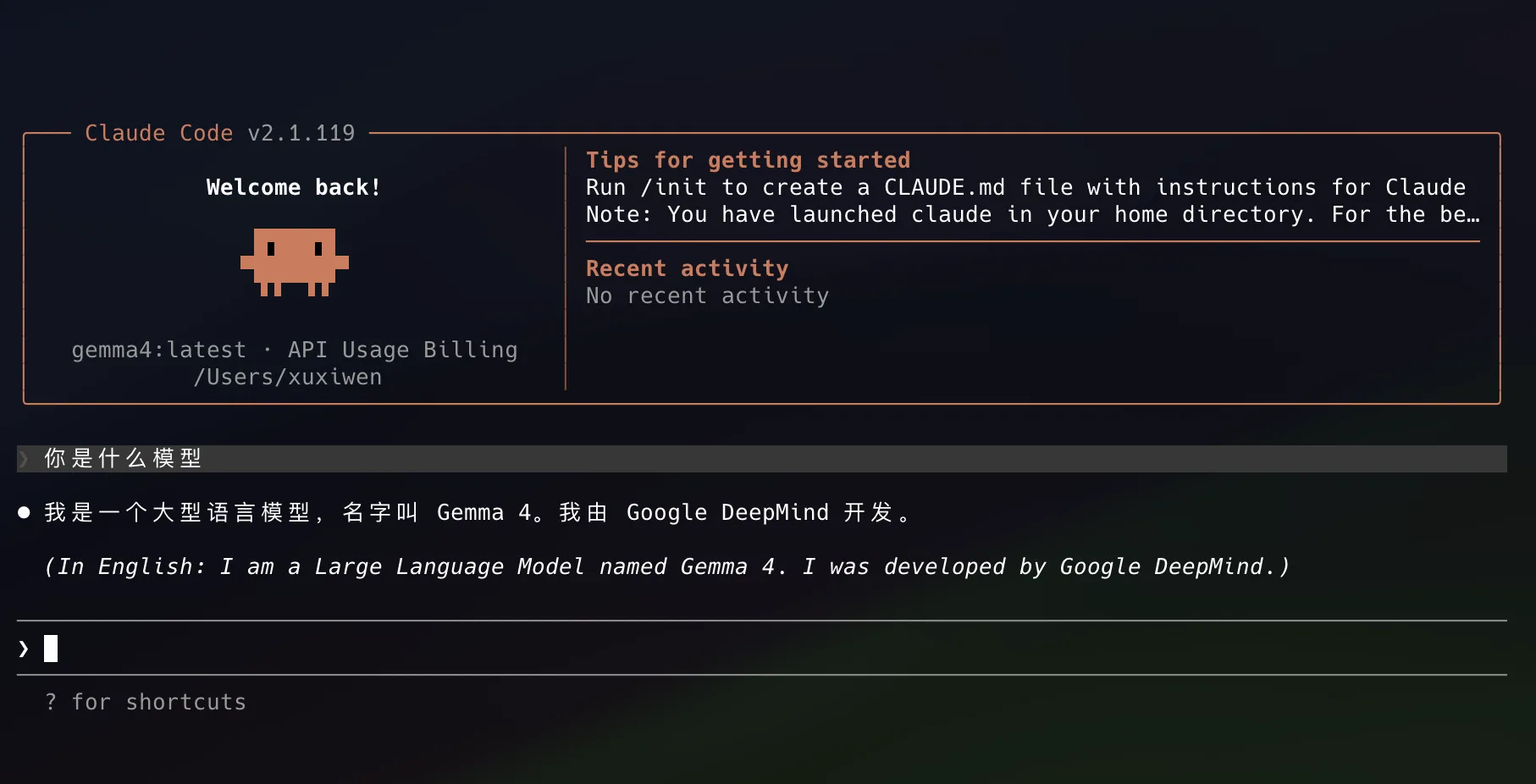
配置成功后效果如下(截图中的模型名仅作示例):
配置 Codex
Codex 与 Claude Code 一样在本地电脑运行,通过 Ollama 的 OpenAI 兼容接口访问实例中的模型。按官方手动配置方式,地址需要追加 /v1。
如果只想在当前终端临时使用,可先导出 Ollama API 地址,再通过 --oss 启动:
export CODEX_OSS_BASE_URL="https://你的自定义服务地址/v1"
codex --oss -m gemma4:31bCODEX_OSS_BASE_URL 只对当前终端会话生效,关闭终端后需要重新设置。
Codex config.toml 参考配置
如果希望长期保存配置,可写入 ~/.codex/config.toml,无需每次手动导出环境变量。
编辑 ~/.codex/config.toml:
nano ~/.codex/config.toml加入以下配置,并将示例公网地址和模型名替换为自己的配置:
[model_providers.rivermind-ollama]
name = "RiverMind Ollama"
base_url = "https://你的自定义服务地址/v1"
[profiles.rivermind-ollama]
model = "gemma4:31b"
model_provider = "rivermind-ollama"启动 Codex:
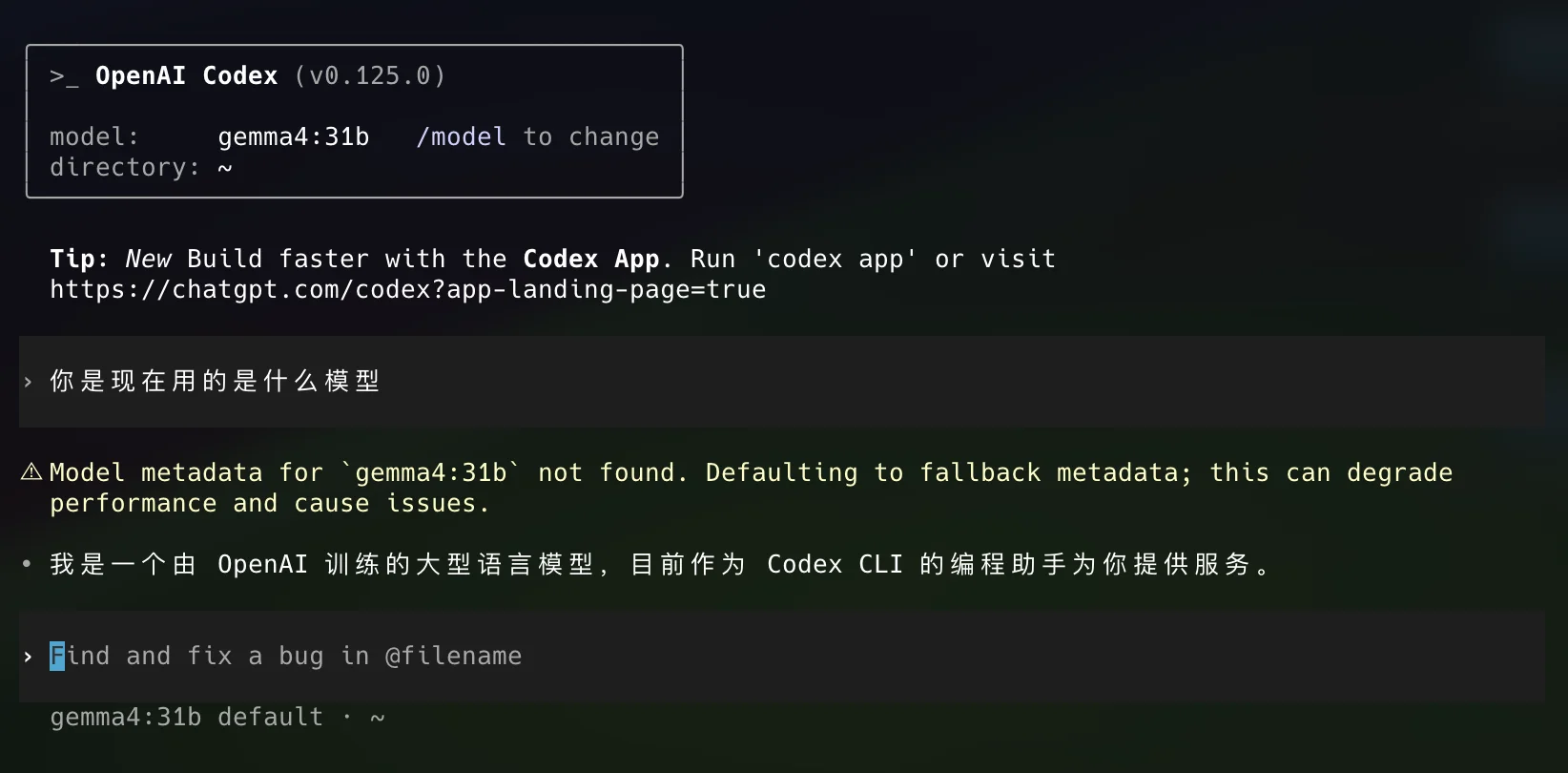
codex --profile rivermind-ollama配置成功后效果如下(截图中的模型名仅作示例):
Ollama 常用命令
| 命令 | 说明 |
|---|---|
ollama -v | 查看 Ollama 版本 |
ollama list | 查看本地已有模型 |
ollama pull gemma4 | 下载示例模型,请替换为实际模型名 |
ollama run gemma4 | 运行示例模型,请替换为实际模型名 |
ollama ps | 查看正在运行的模型 |
ollama stop gemma4 | 停止示例模型,请替换为实际模型名 |
ollama show gemma4 | 查看示例模型信息,请替换为实际模型名 |
ollama rm gemma4 | 删除示例模型,请替换为实际模型名 |
ollama create my-model -f Modelfile | 从 Modelfile 创建模型 |
可选配置
Ollama 参数配置
如需调整 Ollama 运行参数,可手动编辑 /root/ollama-env.sh。更多配置项可参考 Ollama FAQ。
nano /root/ollama-env.sh前文已写入 OLLAMA_MODELS、OLLAMA_HOST、OLLAMA_KEEP_ALIVE,无需重复。按需补充以下进阶参数:
# 默认上下文长度,越大越占用显存/内存
# export OLLAMA_CONTEXT_LENGTH=8192
# 并发配置,显存较小时建议保持较小数值
# export OLLAMA_NUM_PARALLEL=1
# export OLLAMA_MAX_LOADED_MODELS=1
# export OLLAMA_MAX_QUEUE=512
# 显存优化配置,按需开启
# export OLLAMA_FLASH_ATTENTION=1
# export OLLAMA_KV_CACHE_TYPE=q8_0常用参数说明:
| 参数 | 说明 |
|---|---|
OLLAMA_MODELS | 模型文件存储目录 |
OLLAMA_HOST | Ollama API 监听地址 |
OLLAMA_KEEP_ALIVE | 模型空闲后保留在显存/内存中的时间,减少再次调用时的加载等待 |
OLLAMA_CONTEXT_LENGTH | 默认上下文长度 |
OLLAMA_NUM_PARALLEL | 单个模型可并行处理的请求数 |
OLLAMA_MAX_LOADED_MODELS | 同时加载的模型数量上限 |
OLLAMA_MAX_QUEUE | 忙碌时允许排队的请求数量 |
OLLAMA_FLASH_ATTENTION | 启用 Flash Attention |
OLLAMA_KV_CACHE_TYPE | K/V 缓存精度,可选 f16、q8_0、q4_0 |
修改完成后重启 Ollama:
pkill -f "ollama serve" || true
sh /root/start-ollama.sh环境变量变更需要重启 Ollama 服务后才会生效。
如果模型空闲一段时间后再次调用变慢,优先调整 OLLAMA_KEEP_ALIVE。本文默认设置为 1h;显存充足时可改为 -1 常驻,显存紧张时可改为 30m,避免模型长期占用资源。
Open WebUI 可视化界面
Open WebUI 是一个浏览器里的模型对话界面,可连接本机 Ollama 使用模型,提供模型选择、聊天记录、文件问答、知识库/RAG 等常用功能。官方文档参考:Open WebUI Docs。
本文以 18080 端口启动 Open WebUI。
安装 Open WebUI
Open WebUI 官方支持 Docker、pip、uv 等安装方式。本文使用 pip 安装,命令最简单。
使用 pip 安装:
pip install -U open-webui创建数据目录:
mkdir -p /root/open-webui/data启动 Open WebUI
DATA_DIR=/root/open-webui/data \
OLLAMA_BASE_URL=http://127.0.0.1:11434 \
HF_ENDPOINT=https://hf-mirror.com \
WHISPER_MODEL_AUTO_UPDATE=false \
nohup open-webui serve --host 0.0.0.0 --port 18080 > /root/open-webui.log 2>&1 &确认服务已启动:
curl -I http://127.0.0.1:18080/查看日志:
tail -n 50 /root/open-webui.log说明
HF_ENDPOINT 用于配置 Hugging Face 镜像,避免国内网络下启动或下载模型时访问失败。
添加到实例启动脚本(可选)
如果需要 Open WebUI 跟随实例一起启动,将 Open WebUI 启动逻辑保存为独立脚本,再把调用命令追加到 /opt/start.sh;不使用 Open WebUI 可跳过本节。
如已添加过 Open WebUI 启动配置,无需重复执行。
cat > /root/start-openwebui.sh <<'EOF'
#!/bin/bash
# Open WebUI 服务。
mkdir -p /root/open-webui/data
if pgrep -f "[o]pen-webui.*serve" >/dev/null 2>&1; then
exit 0
fi
if ! command -v open-webui >/dev/null 2>&1; then
exit 0
fi
DATA_DIR=/root/open-webui/data \
OLLAMA_BASE_URL=http://127.0.0.1:11434 \
HF_ENDPOINT=https://hf-mirror.com \
WHISPER_MODEL_AUTO_UPDATE=false \
nohup open-webui serve --host 0.0.0.0 --port 18080 > /root/open-webui.log 2>&1 &
EOF写入后执行:
cd /root
chmod +x /root/start-openwebui.sh
# 不覆盖 /opt/start.sh,只追加 Open WebUI 启动入口
touch /opt/start.sh
grep -qxF 'sh /root/start-openwebui.sh' /opt/start.sh \
|| printf '\n# Start Open WebUI\nsh /root/start-openwebui.sh\n' >> /opt/start.sh
# 当前实例立即启动
sh /root/start-openwebui.sh日志文件:
/root/open-webui.log开放端口访问
如需从浏览器访问 Open WebUI,请使用前文开放 18080 端口后得到的公网地址。
首次打开 Open WebUI 页面时,按页面提示创建管理员账号。登录后如模型列表为空,可在 Open WebUI 的连接设置中确认 Ollama 地址为:
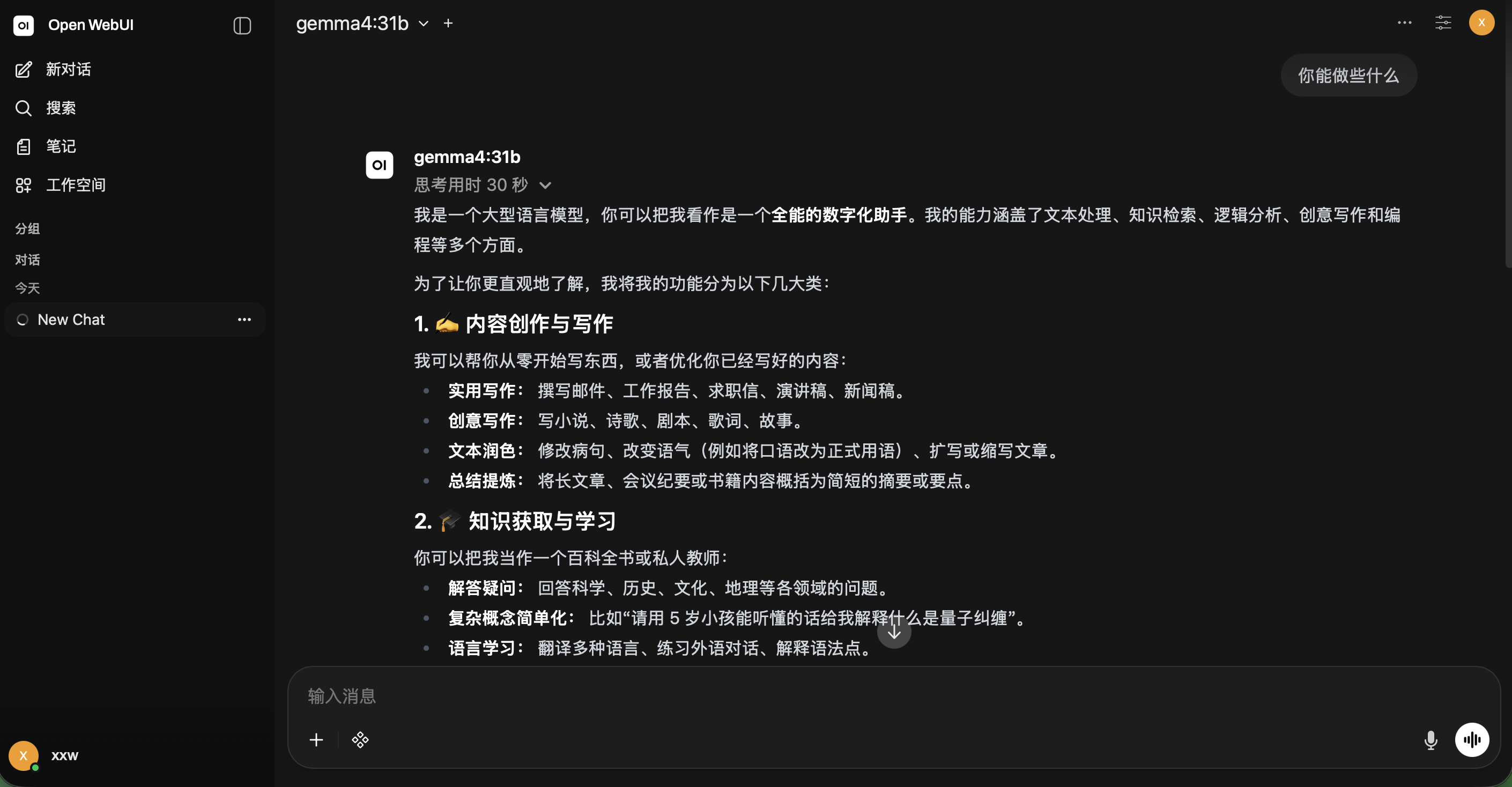
http://127.0.0.1:11434访问成功后界面示例:
常见问题
ollama 命令找不到
先确认安装是否成功,以及命令是否已加入 PATH:
which ollama
ollama -vOllama 没有启动
可通过进程和日志排查启动状态:
pgrep -af "ollama serve"
tail -n 50 /root/ollama.log删除模型
先查看本地模型列表:
ollama list删除指定模型:
ollama rm gemma4如果模型正在运行,需要先停止再删除:
ollama stop gemma4
ollama rm gemma4系统盘空间不足
优先检查模型目录是否已经切换到数据盘:
du -sh /root/rivermind-data/ollama-models如果模型仍然下载到了默认目录,请重新检查 OLLAMA_MODELS 配置,并重启 ollama serve。